Объект многомерных массивов ndarray
Одной из ключевых особенностей NumPy является объект N-мерных
массивов, или ndarray, который является быстрым, гибким контейнером
для больших наборов данных в Python. Массивы позволяют выполнять
математические операции над целыми блоками данных, используя схожий
синтаксис для эквивалентных операций со скалярными элементами.
Рассмотрим пример: создадим небольшой массив случайных данных:
In [6]: import numpy as np
In [7]: data = np.random.randn(2, 3)
In [8]: data
Out[8]:
array([[-0.21595829, -0.8706619 , 0.5635687 ],
[-0.52986695, 1.04566656, 0.57054307]])
In [9]: data * 10
Out[9]:
array([[-2.15958287, -8.70661895, 5.635687 ],
[-5.29866954, 10.45666559, 5.70543068]])
In [10]: data + data
Out[10]:
array([[-0.43191657, -1.74132379, 1.1271374 ],
[-1.05973391, 2.09133312, 1.14108614]])
ndarray является общим контейнером для однородных многомерных
данных, то есть все элементы должны быть одного типа. Каждый массив имеет
атрибут shape — кортеж, указывающий размер каждого измерения, и
атрибут dtype, объект, описывающий тип данных массива:
In [11]: data.shape
Out[11]: (2, 3)
In [12]: data.dtype
Out[12]: dtype('float64')
Создание массива
Простейший способ создания массива — использование функции
array. Она принимает некоторый объект типа последовательностей
(включая другие массивы) и создает новый массив NumPy, содержащий
переданные данные. Например:
In [13]: data1 = [6, 7.5, 8, 0, 1]
In [14]: arr1 = np.array(data1)
In [15]: arr1
Out[15]: array([6. , 7.5, 8. , 0. , 1. ])
Вложенные последовательности, как список списков одинаковой длины, будут преобразованы в многомерный массив:
In [16]: data2 = [[1, 2, 3, 4], [5, 6, 7, 8]]
In [17]: arr2 = np.array(data2)
In [18]: arr2
Out[18]:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
Если явно не указано, np.array пытается вывести подходящий тип
данных для массива, который он создает. Тип данных хранится в
специальном объекте dtype метаданных; например, в двух предыдущих
примерах мы имеем:
In [19]: arr1.dtype
Out[19]: dtype('float64')
In [20]: arr2.dtype
Out[20]: dtype('int64')
Кроме np.array есть несколько других функций для создания новых
массивов:
In [22]: np.zeros(10)
Out[22]: array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
In [23]: np.zeros((3, 6))
Out[23]:
array([[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]])
In [24]: np.empty((2, 3, 2))
Out[24]:
array([[[4.63950122e-310, 0.00000000e+000],
[0.00000000e+000, 0.00000000e+000],
[0.00000000e+000, 0.00000000e+000]],
[[0.00000000e+000, 0.00000000e+000],
[0.00000000e+000, 0.00000000e+000],
[0.00000000e+000, 0.00000000e+000]]])
In [25]: np.arange(15)
Out[25]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
Таблица 1. Функции создания массивов
| Функция | Описание |
array | Преобразует входные данные (список, кортеж, массив или другая последовательность) в ndarray, либо прогнозируя dtype, либо используя заданный dtype; копирует данные по-умолчанию |
asarray | Преобразует входные данные в ndarray, но не копирует их, если аргумент уже типа ndarray |
arange | Подобна встроенной функции range, но возвращает ndarray вместо списка |
ones | Создает массив из единиц заданной формы и dtype |
ones_like | Получает на вход массив и создает массив из единиц с такими же формой и dtype |
zeros и zeros_like | Подобны ones и ones_like, но создают массивы из нулей |
empty и empty_like | Создают новые массивы, выделяя новую память, но не инициализируют их какими-либо значениями, как ones и zeros |
full | Создает массив заданных формы и dtype, при этом все элементы инициализируются заданным значением fill_value |
full_like | Получает на вход массив и создает массив с такими же формой и dtype и значениями fill_value |
eye и identity | Создает квадратную единичную матрицу (с единицами на диагонали и нулями вне нее) размера \( N\times N \) |
Арифметические операции с массивами NumPy
Массивы NumPy, как упоминалось выше, позволяют выполнять операции без использования циклов. Любые арифметические операции между массивами одинакового размера выполняются поэлементно:
In [1]: import numpy as np
In [2]: arr = np.array([[1., 2., 3.], [4., 5., 6.]])
In [3]: arr
Out[3]:
array([[1., 2., 3.],
[4., 5., 6.]])
In [4]: arr * arr
Out[4]:
array([[ 1., 4., 9.],
[16., 25., 36.]])
In [5]: arr - arr
Out[5]:
array([[0., 0., 0.],
[0., 0., 0.]])
Арифметические операции со скалярами распространяют скалярный аргумент к каждому элементу массива:
In [6]: 1 / arr
Out[6]:
array([[1. , 0.5 , 0.33333333],
[0.25 , 0.2 , 0.16666667]])
In [7]: arr ** 0.5
Out[7]:
array([[1. , 1.41421356, 1.73205081],
[2. , 2.23606798, 2.44948974]])
In [8]: arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])
In [9]: arr2
Out[9]:
array([[ 0., 4., 1.],
[ 7., 2., 12.]])
In [10]: arr2 > arr
Out[10]:
array([[False, True, False],
[ True, False, True]])
Основы индексирования и срезы
Существует много способов выбора подмножества данных или элементов массива. Одномерные массивы — это просто, на первый взгляд они аналогичны спискам Python:
In [1]: arr = np.arange(10)
In [2]: arr
Out[2]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [3]: arr[5]
Out[3]: 5
In [4]: arr[5:8]
Out[4]: array([5, 6, 7])
In [5]: arr[5:8] = 12
In [6]: arr
Out[6]: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
Как видно, если присвоить скалярное значение срезу, как например,
arr[5:8] = 12, значение присваивается всем элементам среза. Первым
важным отличием от списков Python заключается в том, что срезы массива
являются представлениями исходного массива. Это означает, что данные
не копируются и любые изменения в представлении будут отражены в
исходном массиве.
Рассмотрим пример. Сначала создадим срез массива arr:
In [7]: arr_slice = arr[5:8]
In [8]: arr_slice
Out[8]: array([12, 12, 12])
Теперь, если мы изменим значения в массиве arr_slice, то они
отразятся в исходном массиве arr:
In [9]: arr_slice[1] = 12345
In [10]: arr
Out[10]:
array([ 0, 1, 2, 3, 4, 12, 12345, 12, 8,
9])
«Голый» срез [:] присвоит все значения в массиве:
In [11]: arr_slice[:] = 64
In [12]: arr
Out[12]: array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
Поскольку NumPy был разработан для работы с очень большими массивами, вы можете представить себе проблемы с производительностью и памятью, если NumPy будет настаивать на постоянном копировании данных.
Замечание
Если вы захотите скопировать срез в массив вместо отображения, нужно
явно скопировать массив, например, arr[5:8].copy().
С массивами более высокой размерности существует больше вариантов. В двумерных массивах каждый элемент это уже не скаляр, а одномерный массив.
In [13]: arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
In [14]: arr2d[2]
Out[14]: array([7, 8, 9])
Таким образом, к отдельному элементу можно получить доступ рекурсивно, либо передать разделенный запятыми список индексов. Например, следующие два примера эквивалентны:
In [15]: arr2d[2]
Out[15]: array([7, 8, 9])
In [16]: arr2d[0][2]
Out[16]: 3
Если в многомерном массиве опустить последние индексы, то возвращаемый объект будет массивом меньшей размерности. Например, создадим массив размерности \( 2 \times 2 \times 3 \):
In [17]: arr3d = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
In [18]: arr3d
Out[18]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
При этом arr3d[0] — массив размерности \( 2 \times 3 \):
In [19]: arr3d[0]
Out[19]:
array([[1, 2, 3],
[4, 5, 6]])
Можно присваивать arr3d[0] как скаляр, так и массивы:
In [20]: old_values = arr3d[0].copy()
In [21]: arr3d[0] = 42
In [22]: arr3d
Out[22]:
array([[[42, 42, 42],
[42, 42, 42]],
[[ 7, 8, 9],
[10, 11, 12]]])
In [23]: arr3d[0] = old_values
In [24]: arr3d
Out[24]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
Аналогично, arr3d[1, 0] возвращает все значения, чьи индексы
начинаются с (1, 0), формируя одномерный массив:
In [25]: arr3d[1, 0]
Out[25]: array([7, 8, 9])
Это выражение такое же, как если бы мы проиндексировали в два этапа:
In [26]: x = arr3d[1]
In [27]: x
Out[27]:
array([[ 7, 8, 9],
[10, 11, 12]])
In [28]: x[0]
Out[28]: array([7, 8, 9])
Индексирование с помощью срезов
Как одномерные объекты, такие как списки, можно получать срезы массивов посредством знакомого синтаксиса:
In [28]: arr
Out[28]: array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
In [29]: arr[1:6]
Out[29]: array([ 1, 2, 3, 4, 64])
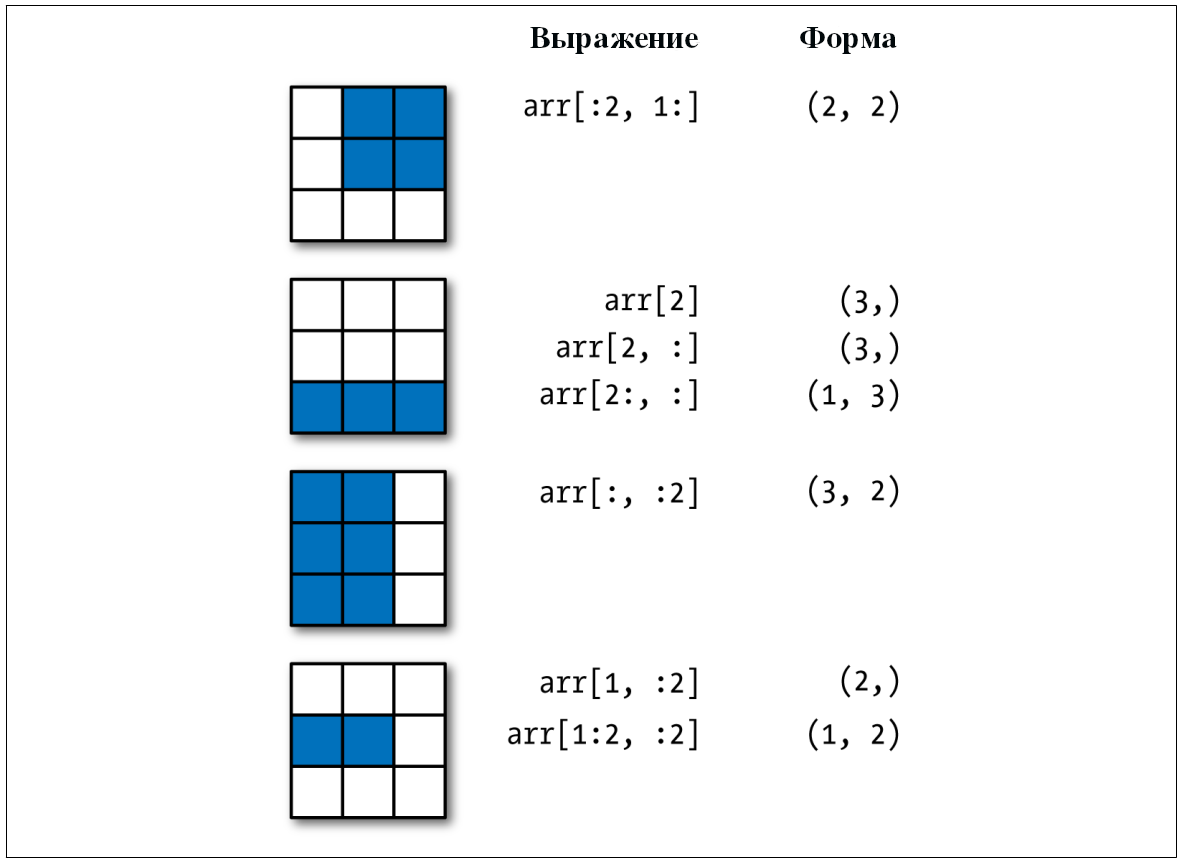
Рассмотрим введенный выше двумерный массив arr2d. Получение срезов
этого массива немного отличается от одномерного:
In [30]: arr2d
Out[30]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [31]: arr2d[:2]
Out[31]:
array([[1, 2, 3],
[4, 5, 6]])
Как видно, мы получили срез вдоль оси 0, первой оси. Срез, таким
образом, выбирает диапазон элементов вдоль оси. Выражение arr2d[:2]
можно прочитать как «выбираем первые две строки массива arr2d».
Можно передавать несколько срезов:
In [32]: arr2d[:2, 1:]
Out[32]:
array([[2, 3],
[5, 6]])
При получении срезов мы получаем только отображения массивов того же числа размерностей. Используя целые индексы и срезы, можно получить срезы меньшей размерности:
In [33]: arr2d[1, :2]
Out[33]: array([4, 5])
In [34]: arr2d[:2, 2]
Out[34]: array([4, 5])
Смотрите рис. 1.
Рисунок 1: Срезы двумерного массива
Логическое (Boolean) индексирование
Рассмотрим следующий пример: пусть есть массив с данными (случайными) и массив, содержащий имена с повторениями:
In [35]: names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
In [36]: data = np.random.randn(7, 4)
In [37]: names
Out[37]: array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='<U4')
In [38]: data
Out[38]:
array([[-0.30602191, -0.30319088, 0.33639925, 0.67844077],
[-0.58702763, -0.29292886, 0.0071339 , -0.72423144],
[ 0.97107817, -0.29963124, 0.25907764, 0.47690155],
[ 0.61053052, -0.62803392, -0.08214009, 0.05142378],
[-0.71103802, 0.05003893, 0.41204829, -0.26279151],
[-0.03198355, 0.82015773, -0.86561954, -0.15198867],
[-0.88311743, -0.81266173, -0.10336611, -0.80341886]])
Предположим, что каждое имя соответствует строке в массиве data, и
мы хотим выбрать все строки с соответствующим именем 'Bob'. Как и
арифметические операции, операции сравнения (такие как ==) с
массивами также векторизованы. Таким образом, сравнение массива
names со строкой 'Bob' возвращает булев массив:
In [39]: names == 'Bob'
Out[39]: array([ True, False, False, True, False, False, False])
Этот булев массив может использоваться при индексировании массива:
In [40]: data[names == 'Bob']
Out[40]:
array([[-0.30602191, -0.30319088, 0.33639925, 0.67844077],
[ 0.61053052, -0.62803392, -0.08214009, 0.05142378]])
Булев массив должен быть той же длины, что и ось массива, по которой осуществляется индексация. Вы даже можете смешивать и сопоставлять логические массивы со срезами или целыми числами (или последовательностями целых чисел).
In [41]: data[names == 'Bob', 2:]
Out[41]:
array([[ 0.33639925, 0.67844077],
[-0.08214009, 0.05142378]])
In [42]: data[names == 'Bob', 3]
Out[42]: array([0.67844077, 0.05142378])
Чтобы выбрать все, кроме 'Bob', можно использовать != или
обращение условия :
In [43]: names != 'Bob'
Out[43]: array([False, True, True, False, True, True, True])
In [44]: data[~(names == 'Bob')]
Out[44]:
array([[-0.58702763, -0.29292886, 0.0071339 , -0.72423144],
[ 0.97107817, -0.29963124, 0.25907764, 0.47690155],
[-0.71103802, 0.05003893, 0.41204829, -0.26279151],
[-0.03198355, 0.82015773, -0.86561954, -0.15198867],
[-0.88311743, -0.81266173, -0.10336611, -0.80341886]])
Оператор может быть полезен при инвертировании общего условия:
In [45]: cond = names == 'Bob'
In [46]: data[~cond]
Out[46]:
array([[-0.58702763, -0.29292886, 0.0071339 , -0.72423144],
[ 0.97107817, -0.29963124, 0.25907764, 0.47690155],
[-0.71103802, 0.05003893, 0.41204829, -0.26279151],
[-0.03198355, 0.82015773, -0.86561954, -0.15198867],
[-0.88311743, -0.81266173, -0.10336611, -0.80341886]])
Выбрав два из трех имен для объединения нескольких логических условий,
можно использовать логические арифметические операторы, такие как & (и) и |
(или):
In [47]: mask = (names == 'Bob') | (names == 'Will')
In [48]: mask
Out[48]: array([ True, False, True, True, True, False, False])
In [49]: data[mask]
Out[49]:
array([[-0.30602191, -0.30319088, 0.33639925, 0.67844077],
[ 0.97107817, -0.29963124, 0.25907764, 0.47690155],
[ 0.61053052, -0.62803392, -0.08214009, 0.05142378],
[-0.71103802, 0.05003893, 0.41204829, -0.26279151]])
Выбор данных из массива с помощью логического индексирования всегда создает копию данных, даже если возвращаемый массив не изменяется.
Предупреждение
Ключевые слова Python and и or не работают с булевыми массивами.
Используйте & (и) и | (или).
Присвоение значений массивам работает обычным образом. Замену
всех отрицательных значений на 0 можно сделать следующим образом:
In [50]: data[data < 0] = 0
In [51]: data
Out[51]:
array([[0. , 0. , 0.33639925, 0.67844077],
[0. , 0. , 0.0071339 , 0. ],
[0.97107817, 0. , 0.25907764, 0.47690155],
[0.61053052, 0. , 0. , 0.05142378],
[0. , 0.05003893, 0.41204829, 0. ],
[0. , 0.82015773, 0. , 0. ],
[0. , 0. , 0. , 0. ]])
Можно также легко присваивать значения целым строкам или столбцам:
In [52]: data[names != 'Joe'] = 7
In [53]: data
Out[53]:
array([[7. , 7. , 7. , 7. ],
[0. , 0. , 0.0071339 , 0. ],
[7. , 7. , 7. , 7. ],
[7. , 7. , 7. , 7. ],
[7. , 7. , 7. , 7. ],
[0. , 0.82015773, 0. , 0. ],
[0. , 0. , 0. , 0. ]])
Необычное индексирование
Необычное индексирование (fancy indexing) — это термин, принятый в NumPy для описания индексации с использованием целочисленных массивов.
Предположим, у нас есть массив размера \( 8 \times 4 \)
In [54]: arr = np.empty((8, 4))
In [55]: for i in range(8):
...: arr[i] = i
In [56]: arr
Out[56]:
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
Чтобы выбрать подмножество строк в определенном порядке, можно просто передать список или массив целых чисел, указывающих желаемый порядок:
In [57]: arr[[4, 3, 0, 6]]
Out[57]:
array([[4., 4., 4., 4.],
[3., 3., 3., 3.],
[0., 0., 0., 0.],
[6., 6., 6., 6.]])
Использование отрицательных индексов выделяет строки с конца:
In [58]: arr[[-3, -5, -7]]
Out[58]:
array([[5., 5., 5., 5.],
[3., 3., 3., 3.],
[1., 1., 1., 1.]])
Передача нескольких индексных массивов делает кое-что другое: выбирается одномерный массив элементов, соответствующий каждому кортежу индексов:
In [59]: arr = np.arange(32).reshape((8, 4))
In [60]: arr
Out[61]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
In [61]: arr[[1, 5, 7, 2], [0, 3, 1, 2]]
Out[61]: array([ 4, 23, 29, 10])
Здесь выбраны элементы с индексами (1, 0), (5, 3), (7, 1) и
(2, 2). Независимо от того какая размерность у массива (в нашем
случае двумерный массив), результат такого индексирования — всегда
одномерный массив.
Поведение индексирования в этом случае немного отличается от того, что могли ожидать некоторые пользователи, а именно: пользователь мог ожидать прямоугольную область, сформированную путем выбора поднабора строк и столбцов матрицы. Ниже представлен один из способов получения таких массивов с помощью необычного индексирования:
In [62]: arr[[1, 5, 7, 2]][:, [0, 3, 1, 2]]
Out[62]:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
Имейте в виду, что необычное индексирование, в отличие от среза, всегда копирует данные в новый массив.
Транспонирование массивов и замена осей
Транспонирование — это особый способ изменения формы массива, который
возвращает представление исходных данных без их копирования. Массивы
имеют метод transpose, а также специальный атрибут T:
In [63]: arr = np.arange(15).reshape((3, 5))
In [64]: arr
Out[64]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
In [65]: arr.T
Out[65]:
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])
При выполнении матричных вычислений эта процедура может выполняться
очень часто, например, при вычислении произведения матриц с помощью
функции np.dot:
In [66]: arr = np.random.randn(6, 3)
In [67]: arr
Out[67]:
array([[-0.31858673, -0.74194068, -0.5057573 ],
[ 0.83588823, -0.53996512, -0.97953623],
[ 0.58273205, 0.67279648, -1.10365259],
[ 0.88643344, 0.01374888, 3.00932538],
[ 1.01328971, 1.62965388, -1.12032883],
[-1.23646751, -0.56660122, -1.24328081]])
In [68]: np.dot(arr.T, arr)
Out[68]:
array([[ 4.48115546, 2.54116501, 1.76883634],
[ 2.54116501, 4.27169117, -0.91830522],
[ 1.76883634, -0.91830522, 14.29025379]])
Для массивов большей размерности метод transpose принимает кортеж с
номерами осей, задающий перестановку осей:
In [69]: arr = np.arange(16).reshape((2, 2, 4))
In [70]: arr
Out[70]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
In [71]: arr.transpose((1, 0, 2))
Out[71]:
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])
Здесь оси были переупорядочены следующим образом: вторая ось стала первой, первая ось — второй, а последняя осталась без изменений.
Простое транспонирование с помощью .T является частным случаем
замены осей. Массивы имеют метод swapaxes, который получает пару
номеров осей и переставляет указанные оси.
In [72]: arr.swapaxes(1, 2)
Out[73]:
array([[[ 0, 4],
[ 1, 5],
[ 2, 6],
[ 3, 7]],
[[ 8, 12],
[ 9, 13],
[10, 14],
[11, 15]]])
Метод swapaxes возвращает представление данных без копирования.