Примеры
Печать символов Юникода
Рассмотрим небольшой, но достаточно поучительный пример использования
метода str.format(), в котором мы увидим применение спецификаторов
формата в реальном контексте. Программа, состоящая всего из 25 строк
выполняемого кода, находится в файле
print_unicode.py. Она импортирует
два модуля, sys и unicodedata и определяет одну функцию –
print_unicode_table(). Рассмотрение примера мы начнем
с запуска программы, чтобы увидеть, что она делает; затем мы
рассмотрим программный код в конце программы, где выполняется вся
фактическая работа; и в заключение рассмотрим функцию, определяемую в
программе.
Terminal> python print_unicode.py
python print_unicode.py Spoked
decimal hex chr name
------- ----- --- ----------------------------------------
10018 2722 ✢ Four Teardrop-Spoked Asterisk
10019 2723 ✣ Four Balloon-Spoked Asterisk
10020 2724 ✤ Heavy Four Balloon-Spoked Asterisk
10021 2725 ✥ Four Club-Spoked Asterisk
10035 2733 ✳ Eight Spoked Asterisk
10043 273B ✻ Teardrop-Spoked Asterisk
10044 273C ✼ Open Centre Teardrop-Spoked Asterisk
10045 273D ✽ Heavy Teardrop-Spoked Asterisk
10051 2743 ❃ Heavy Teardrop-Spoked Pinwheel Asterisk
10057 2749 ❉ Balloon-Spoked Asterisk
10058 274A ❊ Eight Teardrop-Spoked Propeller Asterisk
10059 274B ❋ Heavy Eight Teardrop-Spoked Propeller Asterisk
128943 1F7AF 🞯 Light Five Spoked Asterisk
128944 1F7B0 🞰 Medium Five Spoked Asterisk
128945 1F7B1 🞱 Bold Five Spoked Asterisk
128946 1F7B2 🞲 Heavy Five Spoked Asterisk
128947 1F7B3 🞳 Very Heavy Five Spoked Asterisk
128948 1F7B4 🞴 Extremely Heavy Five Spoked Asterisk
128949 1F7B5 🞵 Light Six Spoked Asterisk
128950 1F7B6 🞶 Medium Six Spoked Asterisk
128951 1F7B7 🞷 Bold Six Spoked Asterisk
128952 1F7B8 🞸 Heavy Six Spoked Asterisk
128953 1F7B9 🞹 Very Heavy Six Spoked Asterisk
128954 1F7BA 🞺 Extremely Heavy Six Spoked Asterisk
128955 1F7BB 🞻 Light Eight Spoked Asterisk
128956 1F7BC 🞼 Medium Eight Spoked Asterisk
128957 1F7BD 🞽 Bold Eight Spoked Asterisk
128958 1F7BE 🞾 Heavy Eight Spoked Asterisk
128959 1F7BF 🞿 Very Heavy Eight Spoked Asterisk
При запуске без аргументов программа выводит таблицу всех символов Юникода, начиная с пробела и до символа с наибольшим возможным кодом. При запуске с аргументом, как показано в примере, выводятся только те строки таблицы, где в названии символов Юникода содержится значение строки-аргумента, переведенной в нижний регистр.
Разберем исходный код программы:
# Start main script
word = None
if len(sys.argv) > 1:
if sys.argv[1] in ("-h", "--help"):
print("usage: {0} [string]".format(sys.argv[0]))
word = 0
else:
word = sys.argv[1].lower()
if word != 0:
print_unicode_table(word)
После инструкций импортирования и определения функции
print_unicode_table() выполнение достигает программного кода,
показанного выше. Сначала предположим, что пользователь не указал в
командной строке искомое слово. Если аргумент командной строки
присутствует и это -h или --help, программа выводит информацию о
порядке использования и устанавливает флаг word в значение 0, указывая
тем самым, что работа завершена. В противном случае в переменную word
записывается копия аргумента, введенного пользователем, с
преобразованием всех символов в нижний регистр. Если значение word не
равно 0, программа выводит таблицу.
При выводе информации о порядке использования применяется спецификатор формата, который представляет собой простое имя формата, в данном случае – порядковый номер позиционного аргумента. Мы могли бы записать эту строку, как показано ниже:
print("usage: {0[0]} [string]".format(sys.argv))
При таком подходе первый символ 0 соответствует порядковому номеру
позиционного аргумента, а [0] — это индекс элемента внутри
аргумента, и такой прием сработает, потому что sys.argv является
списком.
def print_unicode_table(word):
print("decimal hex chr {0:^40}".format("name"))
print("------- ----- --- {0:-<40}".format(""))
code = ord(" ")
end = sys.maxunicode
while code < end:
c = chr(code)
name = unicodedata.name(c, "*** unknown ***")
if word is None or word in name.lower():
print("{0:7} {0:5X} {0:^3c} {1}".format(code, name.title()))
code += 1
Первый вызов str.format() выводит текст "name", отцентрированный в
поле вывода, шириной 40 символов, а второй вызов выводит пустую строку
в поле шириной 40 символов, используя символ - в качестве
символа-заполнителя, с выравниванием по левому краю.
Как вариант, вторую строку функции можно было записать, как показано ниже:
print("------- ----- --- {0}".format("-" * 40))
Здесь мы использовали оператор дублирования строки (*), чтобы
создать необходимую строку, и просто вставили ее в строку формата.
Текущий код символа Юникода сохраняется в переменной code, которая
инициализируется кодом пробела (0x20). В переменную end записывается
максимально возможный код символа Юникода, который может принимать
разные значения в зависимости от того, какая из кодировок
использовалась при компиляции Python.
Внутри цикла while с помощью функции chr() мы получаем символ
Юникода, соответствующий числовому коду. Функция unicodedata.name()
возвращает название заданного символа Юникода, во втором
необязательном аргументе передается имя, которое будет использовано в
случае, когда имя символа не определено.
Если пользователь не указывает аргумент командной строки (word is None)
или аргумент был указан и он входит в состав копии имени символа
Юникода, в которой все символы приведены к нижнему регистру, то
выводится соответствующая строка таблицы.
Мы передаем переменную code методу str.format() один раз, но в
строке формата она используется трижды. Первый раз – при выводе
значения code как целого числа в поле с шириной 7 символов (по
умолчанию в качестве символа-заполнителя используется пробел, поэтому
нет необходимости явно указывать его). Второй раз – при выводе
значения code как целого числа в шестнадцатеричном формате символами
верхнего регистра в поле шириной 5 символов. И третий раз – при выводе
символа Юникода, соответствующего значению code, с помощью
спецификатора формата c, отцентрированного в поле с минимальной
шириной 3 символа. Обратите внимание, что нам не потребовалось
указывать тип d в первом спецификаторе формата, потому что он
подразумевается по умолчанию для целых чисел. Второй аргумент –
это имя символа Юникода, которое выводится с помощью метода
str.title(), в результате которого первый символ каждого слова
преобразуется к верхнему регистру, а остальные символы – к нижнему.
Решение квадратного уравнения
Квадратные уравнения – это уравнения вида \( ax^2 + bx + c = 0 \), где \( a \ne 0 \), описывающие параболу. Корни таких уравнений находятся по формуле $$ x = \frac{-b \pm \sqrt{b^2-4ac}}{2a}. $$ Часть формулы \( b^2 – 4ac \) называется дискриминантом – если это положительная величина, уравнение имеет два действительных корня, если дискриминант равен нулю – уравнение имеет один действительный корень, и в случае отрицательного значения уравнение имеет два комплексных корня. Мы напишем программу, которая будет принимать от пользователя коэффициенты \( a \), \( b \) и \( c \) (коэффициенты \( b \) и c могут быть равны нулю) и затем вычислять и выводить его корень или корни.
Для начала посмотрим, как работает программа:
Terminal> quadratic.py
ax 2 + bx + c = 0
enter a: 2.5
enter b: 0
enter c: -7.25
2.5x 2 + 0.0x + -7.25 = 0 → x = 1.70293863659 or x = -1.70293863659
С коэффициентами \( 1.5 \), \( -3 \) и \( 6 \) программа выведет (некоторые цифры обрезаны):
Terminal> 1.5x 2 + -3.0x + 6.0 = 0 → x = (1+1.7320508j) or x = (1-1.7320508j)
Теперь обратимся к программному коду,
который начинается тремя инструкциями import:
import cmath
import math
import sys
Нам необходимы обе математические библиотеки для работы с числами типа
float и complex, так как функции, вычисляющие квадратный
корень из вещественных и комплексных чисел, отличаются. Модуль
sys нам необходим, так как в нем определена константа
sys.float_info.epsilon, которая потребуется нам для сравнения
вещественных чисел со значением 0.
Нам также необходима функция, которая будет получать от пользова- теля число с плавающей точкой:
def get_float(msg, allow_zero):
x = None
while x is None:
try:
x = float(input(msg))
if not allow_zero and abs(x) < sys.float_info.epsilon:
print("zero is not allowed")
x = None
except ValueError as err:
print(err)
return x
Эта функция выполняет цикл, пока пользователь не введет допустимое
число с плавающей точкой (например, 0.5, -9, 21, 4.92), и допускает
ввод значения 0, только если аргумент allow_zero имеет значение True.
Вслед за определением функции get_float() выполняется оставшаяся
часть программного кода. Мы разделим его на три части и начнем со
взаимодействия с пользователем:
print("ax\N{SUPERSCRIPT TWO} + bx + c = 0")
a = get_float("enter a: ", False)
b = get_float("enter b: ", False)
c = get_float("enter c: ", False)
Благодаря функции get_float() получить значения коэффициентов a,
b и c оказалось очень просто. Второй аргумент функции сообщает, когда
значение 0 является допустимым.
x1 = None
x2 = None
discriminant = (b ** 2) - (4 * a * c)
if discriminant == 0:
x1 = -(b / (2 * a))
else:
if discriminant > 0:
root = math.sqrt(discriminant)
else: # discriminant < 0
root = cmath.sqrt(discriminant)
x1 = (-b + root) / (2 * a)
x2 = (-b - root) / (2 * a)
Программный код выглядит несколько иначе, чем формула, потому
что мы начали вычисления с определения значения дискриминанта.
Если дискриминант равен 0, мы знаем, что уравнение имеет
единственное действительное решение и можно сразу же вычислить его. В
противном случае мы вычисляем действительный или комплексный
квадратный корень из дискриминанта и находим два корня уравнения.
equation = ("{0}x\N{SUPERSCRIPT TWO} + {1}x + {2} = 0"
" \N{RIGHTWARDS ARROW} x = {3}").format(a, b, c, x1)
if x2 is not None:
equation += " or x = {0}".format(x2)
print(equation)
Мы не использовали сколько-нибудь сложного форматирования, поскольку форматирование, используемое по умолчанию для чисел с плавающей точкой в языке Python, прекрасно подходит для этого примера, но мы использовали некоторые имена Юникода для вывода пары специальных символов.
Представление таблицы csv в HTML
Часто бывает необходимо представить данные в формате HTML. В этом подразделе мы разработаем программу, которая читает данные из файла в простом формате CSV (Comma Separated Value – значения, разделенные запятыми) и выводит таблицу HTML, содержащую эти данные. В составе Python присутствует мощный и сложный модуль для работы с форматом CSV и похожими на него – модуль csv, но здесь мы будем выполнять всю обработку вручную.
В формате CSV каждая запись располагается на одной строке, а поля внутри записи отделяются друг от друга запятыми. Каждое поле может быть либо строкой, либо числом. Строки должны окружаться апострофами или кавычками, а числа не должны окружаться кавычками, если они не содержат запятые. Внутри строк допускается присутствие запятых, и они не должны интерпретироваться как разделители полей. Мы будем исходить из предположения, что первая запись в файле содержит имена полей. На выходе будет воспроизводиться таблица в формате HTML с выравниванием текста по левому краю (по умолчанию для HTML) и с выравниванием чисел по правому краю, по одной строке на запись и по одной ячейке на поле.
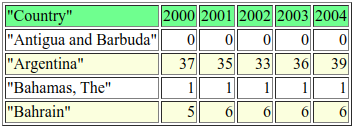
Ниже приводится маленький фрагмент файла с данными:
"COUNTRY",2000,2001,2002,2003,2004
"ANTIGUA AND BARBUDA",0,0,0,0,0
"ARGENTINA",37,35,33,36,39
"BAHAMAS, THE",1,1,1,1,1
"BAHRAIN",5,6,6,6,6
Предположим, что данные находятся в файле sample.csv и выполнена комадна
Terminal> python csv2html.py < sample.csv > sample.html
тогда файл sample.html должен содержать примерно следующее:
<table border='1'>
<tr bgcolor='lightgreen'>
<td>"Country"</td>
<td align='right'>2000</td>
<td align='right'>2001</td>
<td align='right'>2002</td>
<td align='right'>2003</td>
<td align='right'>2004</td>
</tr>
<tr bgcolor='white'>
<td>"Antigua and Barbuda"</td>
<td align='right'>0</td>
<td align='right'>0</td>
<td align='right'>0</td>
<td align='right'>0</td>
<td align='right'>0</td>
</tr>
<tr bgcolor='lightyellow'>
<td>"Argentina"</td>
<td align='right'>37</td>
<td align='right'>35</td>
<td align='right'>33</td>
<td align='right'>36</td>
<td align='right'>39</td>
</tr>
<tr bgcolor='white'>
<td>"Bahamas, The"</td>
<td align='right'>1</td>
<td align='right'>1</td>
<td align='right'>1</td>
<td align='right'>1</td>
<td align='right'>1</td>
</tr>
<tr bgcolor='lightyellow'>
<td>"Bahrain"</td>
<td align='right'>5</td>
<td align='right'>6</td>
<td align='right'>6</td>
<td align='right'>6</td>
<td align='right'>6</td>
</tr>
</table>
На рис. показано, как выглядит полученная таблица в веб-броузере.
Рисунок 5: Таблица, произведенная программой csv2html.py, в броузере
Теперь, когда мы увидели, как используется программа и что она делает, можно приступать к изучению программного кода.
Последняя инструкция в программе – это простой вызов функции:
main()
Хотя в языке Python не требуется явно указывать точку входа в
программу, как в некоторых других языках программирования, тем не
менее является распространенной практикой создание в программе на
языке Python функции с именем main(), которая вызывается для
выполнения обработки. Поскольку функция не может вызываться до того,
как она будет определена, мы должны вставлять вызов main() только
после того, как данная функция будет определена. Порядок следования
функций в файле (то есть порядок, в котором они создаются) не
имеет значения.
В программе csv2html.py первой
вызываемой функцией является функция main(), которая в свою очередь
вызывает функции print_start() и print_line(). Функция
print_line() вызывает функции extract_fields() и escape_html().
Когда интерпретатор Python читает файл, он начинает делать это с
самого начала. Поэтому сначала будет выполнен импорт (если он есть),
затем будет создана функция main(), а затем будут созданы остальные
функции – в том порядке, в каком они следуют в файле. Когда
интерпретатор, наконец, достигнет вызова main() в конце файла, все
функции, которые вызываются функцией main() (и все функции, которые
вызываются этими функциями), будут определены. Выполнение обработки,
как и следовало ожидать, начинается в точке вызова функции main().
Рассмотрим все функции по порядку, начиная с функции main().
def main():
maxwidth = 100
print_start()
count = 0
while True:
try:
line = input()
if count == 0:
color = "lightgreen"
elif count % 2:
color = "white"
else:
color = "lightyellow"
print_line(line, color, maxwidth)
count += 1
except EOFError:
break
print_end()
Переменная maxwidth используется для хранения числа символов в
ячейке. Если поле больше, чем это число, часть строки отсекается и на
место отброшенного текста добавляется многоточие. Программный код
функций print_start(), print_line() и print_end() будет приведен
чуть ниже. Цикл while выполняет обход всех входных строк – это могут
быть строки, вводимые пользователем с клавиатуры, но мы предполагаем,
что данные будут перенаправлены из файла. Далее выбирается цвет фона и
вызывается функция print_line(), которая выводит строку в виде строки
таблицы в формате HTML.
def print_start():
print("<table border='1'>")
def print_end():
print("</table>")
Мы могли бы не создавать эти две функции и просто вставить
соответствующие вызовы print() в функцию main(). Но мы предпочитаем
выделять логику, так как это делает реализацию более гибкой, хотя
в этом маленьком примере гибкость не имеет большого значения.
def print_line(line, color, maxwidth):
print("<tr bgcolor='{0}'>".format(color))
fields = extract_fields(line)
for field in fields:
if not field:
print("<td></td>")
else:
number = field.replace(",", "")
try:
x = float(number)
print("<td align='right'>{0:d}</td>".format(round(x)))
except ValueError:
field = field.title()
field = field.replace(" And ", " and ")
field = escape_html(field)
if len(field) <= maxwidth:
print("<td>{0}</td>".format(field))
else:
print("<td>{0:.{1}} ...</td>".format(field, maxwidth))
print("</tr>")
Мы не можем использовать метод str.split(",") для разбиения каждой
строки на поля, потому что запятые могут находиться внутри строк в
кавычках. Поэтому мы возложили эту обязанность на функцию
extract_fields(). Получив список строк полей (в виде строк без
окружающих их кавычек), мы выполняем обход списка и создаем для
каждого поля ячейку таблицы.
Если поле пустое, мы выводим пустую ячейку. Если поле было заключено в
кавычки, это может быть строка или число в кавычках, содержащее
символы запятой, например "1,566". Учитывая такую возможность, мы
создаем копию поля без запятых и пытаемся преобразовать ее в число
типа float. Если преобразование удалось, мы определяем выравнивание
в ячейке по правому краю, а значение поля округляется до ближайшего
целого, которое и выводится. Если преобразование не удалось,
следовательно, поле содержит строку. В этом случае мы с помощью метода
str.title() изменяем регистр символов и замещаем слово «And» на слово
«and», устраняя побочный эффект действия метода
str.title(). Затем выполняется экранирование специальных символов
HTML и выводится либо поле целиком, либо первые maxwidth символов
с добавлением многоточия. Простейшей альтернативой использованию
вложенного поля замены в строке формата является получение
среза строки, например:
print("<td>{0} ...</td>".format(field[:maxwidth]))
Еще одно преимущество такого подхода состоит в том, что он требует меньшего объема ввода с клавиатуры.
def extract_fields(line):
fields = []
field = ""
quote = None
for c in line:
if c in "\"'":
if quote is None: # начало строки в кавычках
quote = c
elif quote == c: # конец строки в кавычках
quote = None
else:
field += c
# другая кавычка внутри строки в кавычках
continue
if quote is None and c == ",": # end of a field
fields.append(field)
field = ""
else:
field += c
# добавить символ в поле
if field:
fields.append(field) # добавить последнее поле в список
return fields
Эта функция читает символы из строки один за другим и накапливает список полей, где каждое поле – это строка без окружающих ее кавычек. Функция способна обрабатывать поля, не заключенные в кавычки, и поля, заключенные в кавычки или в апострофы, корректно обрабатывая запятые и кавычки (апострофы в строках, заключенных в кавычки, и кавычки в строках, заключенных в апострофы).
def escape_html(text):
text = text.replace("&", "&")
text = text.replace("<", "<")
text = text.replace(">", ">")
return text
Эта функция просто замещает каждый специальный символ HTML соответствующей ему сущностью языка HTML. В первую очередь, конечно, мы должны заменить символ амперсанда и угловые скобки, хотя порядок не имеет никакого значения.