Строки
Строки в языке Python представлены неизменяемым типом данных str,
который хранит последовательность символов Юникода. Тип данных str
может вызываться как функция для создания строковых объектов – без
аргументов возвращается пустая строка; с аргументом, который не
является строкой, возвращается строковое представление аргумента; а в
случае, когда аргумент является строкой, возвращается его
копия. Функция str() может также использоваться как функция
преобразования. В этом случае первый аргумент должен быть строкой или
объектом, который можно преобразовать в строку, а, кроме того, функции
может быть передано до двух необязательных строковых аргументов, один
из которых определяет используемую кодировку, а второй определяет
порядок обработки ошибок кодирования.
Литералы строк создаются с использованием кавычек или апострофов, при этом важно, чтобы с обоих концов литерала использовались кавычки одного и того же типа. В дополнение к этому мы можем использовать строки в тройных кавычках, то есть строки, которые начинаются и заканчиваются тремя символами кавычки (либо тремя кавычками, либо тремя апострофами). Например:
text = """Строки в тройных кавычках могут включать 'апострофы' и "кавычки"
без лишних формальностей. Мы можем даже экранировать символ перевода строки \,
благодаря чему данная конкретная строка будет занимать всего две строки."""
Если нам потребуется использовать кавычки в строке, это можно сделать без лишних формальностей – при условии, что они отличаются от кавычек, ограничивающих строку; в противном случае символы кавычек или апострофов внутри строки следует экранировать:
a = "Здесь 'апострофы' можно не экранировать, а \"кавычки\" придется."
b = 'Здесь \'апострофы\' придется экранировать, а "кавычки" не обязательно.'
В языке Python символ перевода строки интерпретируется как завершающий
символ инструкции, но не внутри круглых скобок (()), квадратных
скобок ([]), фигурных скобок ({}) и строк в тройных кавычках.
Символы перевода строки могут без лишних формальностей использоваться
в строках в тройных кавычках, и мы можем включать символы перевода
строки в любые строковые литералы с помощью экранированной
последовательности \n.
Все экранированные последовательности, допустимые в языке Python, перечислены в табл. 2.6.
Таблица 5. Функции и константы модуля math
| Последовательность | Значение |
\переводстроки | Экранирует (то есть игнорирует) символ перевода строки |
\\ | Символ обратного слеша (\) |
\' | Апостроф (') |
\" | Кавычка (") |
\a | Символ ASCII «сигнал» (bell, BEL) |
\b | Символ ASCII «забой» (backspace, BS) |
\f | Символ ASCII «перевод формата» (formfeed, FF) |
\n | Символ ASCII «перевод строки» (linefeed, LF) |
\N{название} | Символ Юникода с заданным названием |
\ooo | Символ с заданным восьмеричным кодом |
\r | Символ ASCII «возврат каретки» (carriage return, CR) |
\t | Символ ASCII «табуляция» (tab, TAB) |
\uhhhh | Символ Юникода с указанным 16-битовым шестнадцатеричным значением |
\Uhhhhhhhh | Символ Юникода с указанным 32-битовым шестнадцатеричным значением |
\v | Символ ASCII «вертикальная табуляция» (vertical tab, VT) |
\xhh | Символ с указанным 8-битовым шестнадцатеричным значением |
Если потребуется записать длинный строковый литерал, занимающий две или более строк, но без использования тройных кавычек, то можно использовать один из приемов, показанных ниже:
t = "Это не самый лучший способ объединения двух длинных строк, " + \
"потому что он основан на использовании неуклюжего экранирования"
s = ("Это отличный способ объединить две длинные строки, "
" потому что он основан на конкатенации строковых литералов.")
Обратите внимание, что во втором случае для создания единственного
выражения мы должны были использовать круглые скобки – без этих
скобок переменной s была бы присвоена только первая строка, а наличие
второй строки вызвало бы исключение IndentationError.
Сравнение строк
Строки поддерживают обычные операторы сравнения <, <=, ==, !=,
> и >=. Эти операторы выполняют побайтовое сравнение строк в памяти.
К сожалению, возникают две проблемы при сравнении, например,
строк в отсортированных списках. Обе проблемы проявляются во всех
языках программирования и не являются характерной особенностью
Python.
Первая проблема связана с тем, что символы Юникода могут быть представлены двумя и более последовательностями байтов.
Вторая проблема заключается в том, что порядок сортировки некоторых символов зависит от конкретного языка.
Получение срезов строк
Отдельные элементы последовательности, а, следовательно, и отдельные
символы в строках, могут извлекаться с помощью оператора доступа к
элементам ([]). В действительности этот оператор намного более
универсальный и может использоваться для извлечения не только одного
символа, но и целых комбинаций (подпоследовательностей) элементов или
символов, когда этот оператор используется в контексте оператора
извлечения среза.
Для начала мы рассмотрим возможность извлечения отдельных
символов. Нумерация позиций символов в строках начинается с 0 и
продолжается до значений длины строки минус 1. Однако допускается
использовать и отрицательные индексы – в этом случае отсчет начинается
с последнего символа и ведется в обратном направлении к первому
символу. На рис. 1 показано, как нумеруются
позиции символов в строке, если предположить, что было выполнено
присваивание s = "Light ray".
Рисунок 1: Номера позиций символов в строке
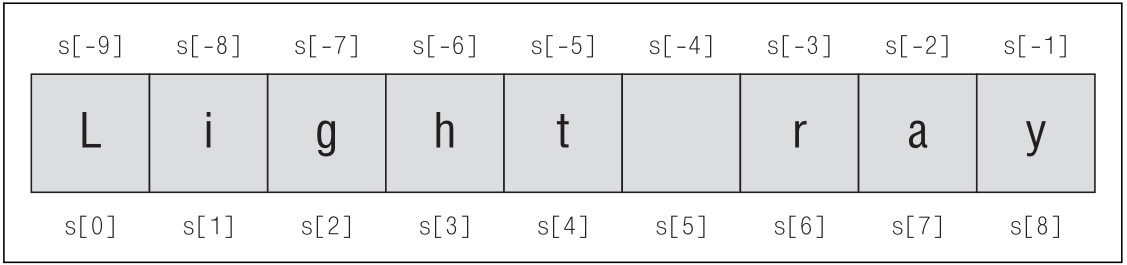
Отрицательные индексы удивительно удобны, особенно индекс -1,
который всегда соответствует последнему символу строки. Попытка
обращения к индексу, находящемуся за пределами строки (или к любому
индексу в пустой строке), будет вызывать исключение IndexError.
Оператор получения среза имеет три формы записи:
seq[start]
seq[start:end]
seq[start:end:step]
Ссылка seq может представлять любую последовательность, такую как
список, строку или кортеж. Значения start, end и step должны быть
целыми числами (или переменными, хранящими целые числа). Первая форма
— это запись оператора доступа к элементам: с ее помощью извлекается
элемент последовательности с индексом start. Вторая форма записи
извлекает подстроку, начиная с элемента с индексом start и заканчивая
элементом с индексом end, не включая его.
При использовании второй формы записи (с одним двоеточием) мы можем
опустить любой из индексов. Если опустить начальный индекс, по
умолчанию будет использоваться значение 0. Если опустить конечный
индекс, по умолчанию будет использоваться значение len(seq).
Это означает, что если опустить оба индекса, например, s[:], это будет
равносильно выражению s[0:len(s)], и в результате будет извлечена,
то есть скопирована, последовательность целиком.
На рис. 2 приводятся некоторые примеры
извлечения срезов из строки s, которая получена в результате
присваивания s = "The waxwork man".
Рисунок 2: Извлечение срезов из последовательности
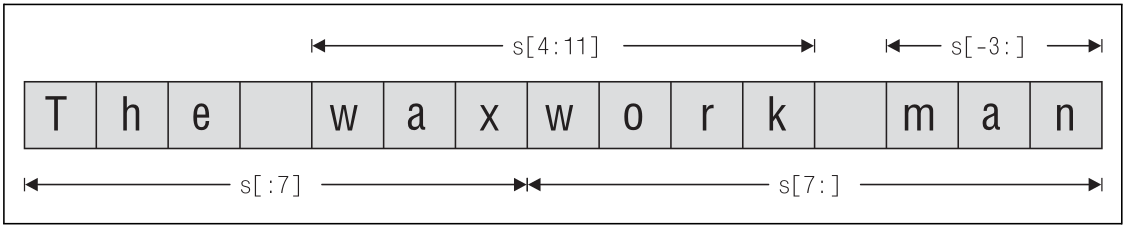
Один из способов вставить подстроку в строку состоит в смешивании операторов извлечения среза и операторов конкатенации. Например:
>>> s = s[:12] + "wo" + s[12:]
>>> s
'The waxwork woman'
Кроме того, поскольку текст «wo» присутствует в оригинальной строке,
тот же самый эффект можно было бы получить путем присваивания значения
выражения s[:12] + s[7:9] + s[12:].
Оператор конкатенации + и добавления подстроки += не
особенно эффективны, когда в операции участвует множество строк. Для
объединения большого числа строк обычно лучше использовать метод
str.join(), с которым мы познакомимся в следующем подразделе.
Третья форма записи (с двумя двоеточиями) напоминает вторую форму, но
в отличие от нее значение step определяет, с каким шагом следует
извлекать символы. Как и при использовании второй формы записи, мы
можем опустить любой из индексов. Если опустить начальный
индекс, по умолчанию будет использоваться значение 0, при условии,
что задано неотрицательное значение step; в противном случае начальный
индекс по умолчанию получит значение -1. Если опустить конечный
индекс, по умолчанию будет использоваться значение len(seq),
при условии, что задано неотрицательное значение step; в противном
случае конечный индекс по умолчанию получит значение индекса перед
началом строки. Мы не можем опустить значение step, и оно не может
быть равно нулю – если задание шага не требуется, то следует
использовать вторую форму записи (с одним двоеточием), в которой шаг
выбора элементов не указывается.
На рис. 3 приводится пара примеров извлечения разреженных срезов из
строки s, которая получена в результате присваивания
s = "he ate camel food".
Рисунок 3: Извлечение разреженных срезов
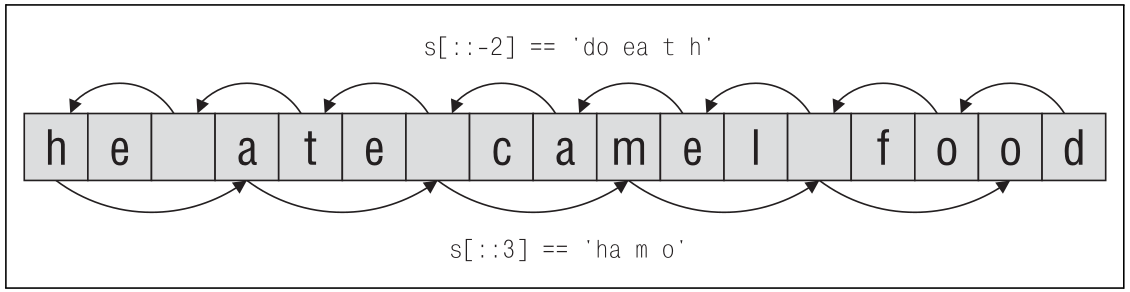
Здесь мы использовали значения по умолчанию для начального и ко- нечного индексов, то есть извлечение среза s[:: – 2] начинается с по- следнего символа строки и извлекается каждый второй символ по на- правлению к началу строки. Аналогично извлечение среза s[::3] на- чинается с первого символа строки и извлекается каждый третий сим- вол по направлению к концу строки. Существует возможность комбинировать индексы с размером шага, как показано на рис. 4.
Рисунок 4: Извлечение срезов из последовательности с определенным шагом
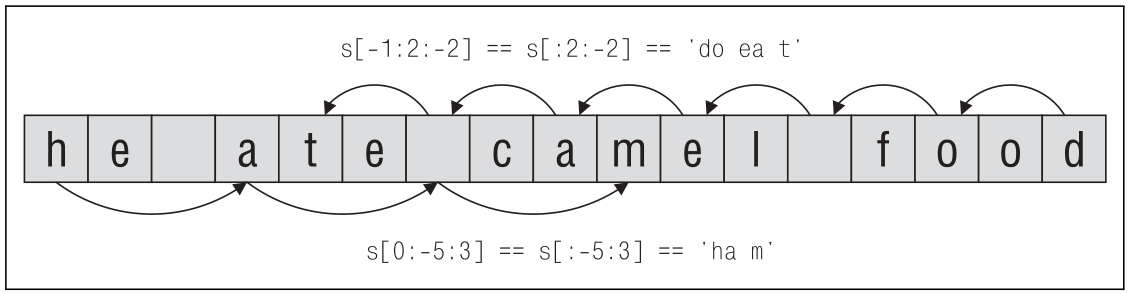
Операция извлечения элементов с определенным шагом часто применяется к последовательностям, отличным от строк, но один из ее вариантов часто применяется к строкам:
Операторы и методы строк
Поскольку строки относятся к категории неизменяемых
последовательностей, все функциональные возможности, применимые к
неизменяемым последовательностям, могут использоваться и со
строками. Сюда входят оператор проверки на вхождение in, оператор
конкатенации +, оператор добавления в конец +=, оператор
дублирования * и комбинированный оператор присваивания с
дублированием *=. Применение всех этих операторов в контексте строк
мы обсудим в этом подразделе, а также обсудим большинство строковых
методов. В табл. 2.7 приводится перечень некоторых строковых методов.
Так как строки являются последовательностями, они являются объектами,
имеющими «размер», и поэтому мы можем вызывать функцию len(),
передавая ей строки в качестве аргумента. Возвращаемая функцией длина
представляет собой количество символов в строке (ноль – для пустых
строк).
Мы уже знаем, что перегруженная версия оператора + для строк
выполняет операцию конкатенации. В случаях, когда требуется объединить
множество строк, лучше использовать метод str.join(). Метод
принимает в качестве аргумента последовательность (то есть список
или кортеж строк) и объединяет их в единую строку, вставляя между
ними строку, относительно которой был вызван метод. Например:
>>> treatises = ["Arithmetica", "Conics", "Elements"]
>>> " ".join(treatises)
'Arithmetica Conics Elements'
>>> "-<>-".join(treatises)
'Arithmetica-<>-Conics-<>-Elements'
>>> "".join(treatises)
'ArithmeticaConicsElements'
Метод str.join() может также использоваться в комбинации со
встроенной функцией reversed(), которая переворачивает строку –
например, "".join(reversed(s)), хотя тот же результат может быть
получен более кратким оператором извлечения разреженного среза –
например, s[:: – 1].
Оператор * обеспечивает возможность дублирования строки:
>>> s = "=" * 5
>>> print(s)
=====
>>> s *= 10
>>> print(s)
==================================================
Как показано в примере, мы можем также использовать комбинированный оператор присваивания с дублированием.
Форматирование строк с помощью метода str.format()
Метод str.format() представляет собой очень мощное и гибкое средство
создания строк. Использование метода str.format() в простых случаях
не вызывает сложностей, но для более сложного форматирования нам
необходимо изучить синтаксис форматирования.
Метод str.format() возвращает новую строку, замещая поля в
контекстной строке соответствующими аргументами. Например:
>>> "The novel '{0}' was published in {1}".format("Hard Times", 1854)
"The novel 'Hard Times' was published in 1854"
Каждое замещаемое поле идентифицируется именем поля в фигурных
скобках. Если в качестве имени поля используется целое число, оно
определяет порядковый номер аргумента, переданного методу
str.format(). Поэтому в данном случае поле с именем 0 было замещено
первым аргументом, а поле с именем 1 – вторым аргументом.
Если бы нам потребовалось включить фигурные скобки в строку формата, мы могли бы сделать это, дублируя их, как показано ниже:
>>> "{{{0}}} {1} ;-}}".format("I'm in braces", "I'm not")
"{I'm in braces} I'm not ;-}"
Если попытаться объединить строку и число, интерпретатор Python
совершенно справедливо возбудит исключение TypeError. Но это легко
можно сделать с помощью метода str.format():
>>> "{0}{1}".format("The amount due is $", 200)
'The amount due is $200'
С помощью str.format() мы также легко можем объединять строки
(хотя для этой цели лучше подходит метод str.join()):
>>> x = "three"
>>> s ="{0} {1} {2}"
>>> s = s.format("The", x, "tops")
>>> s
'The three tops'
В следующем разделе мы рассмотрим применение функции str.format().